AIガバナンスの方法を考える時、AIをブラックボックスと捉えて学習用データやガードレールのことを考えることが多くあります。特にLLMに対してその傾向が強いと思いますが、もう少しLLMの中身に目を向けてAIガバナンスを進化させることができるのではないかと考え始めました。
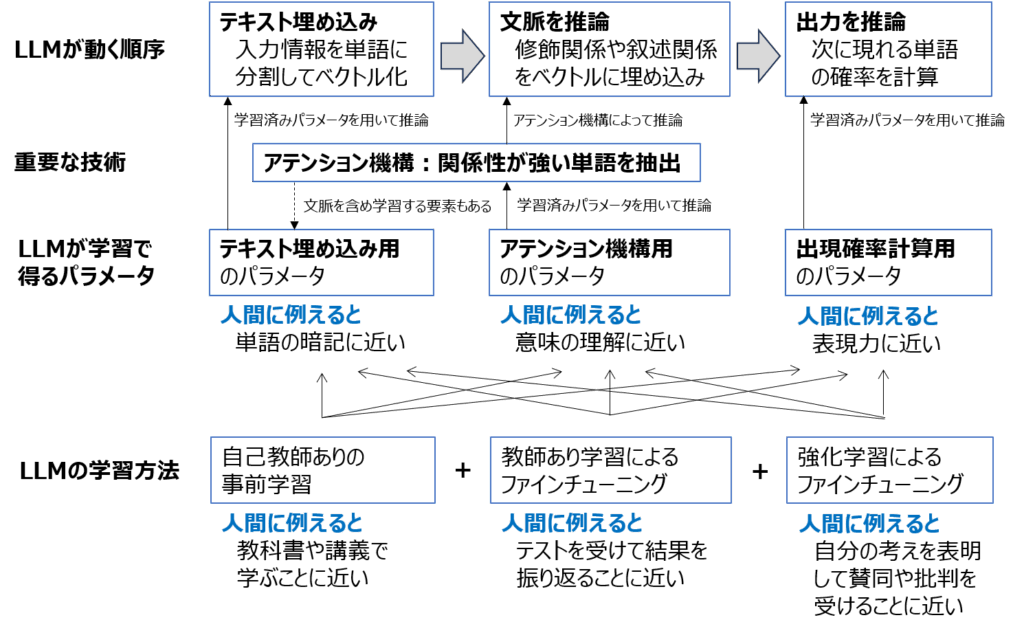
LLMの実装には活性化関数や正規化など機械学習モデルと同様な計算処理のための多様な技術が用いられていますが、LLMがLLMであるための技術は概ね次の3フェーズで実行されています。
<フェーズ1>テキスト埋め込み
入力を単語(トークン)に分割してベクトル化します。この時、意味が近い単語が似たベクトルになるようにします。
<フェーズ2>文脈を推論
単語間の修飾関係や叙述関係を推論して、文脈の中で関係性が強い単語を表すベクトルを生成します。
<フェーズ3>出力を推論
LLMの説明でよく使われる「次の単語の発生確率」を推論します。フェーズ2で文脈を推論した結果を用いて次の単語を推論することにより自然な受け答えが可能になります。
そして、最も重要な技術はアテンション機構です。これは、フェーズ1で文脈を加味して単語の意味を学習したり、フェーズ2で単語間の関係性を元にして文脈を推論するために用いられます。
それぞれのフェーズを実行する際に用いるパラメータはLLMの学習によって得ます。それぞれのパラメータを学習から得ることは、人間が学びを深める過程に似ています。
・テキスト埋め込み用のパラメータ
人間に例えると、単語を暗記することに似ている
・アテンション機構用のパラメータ
人間に例えると、文章の意味を理解することに似ている
・(次の単語の)出現確率計算用のパラメータ
人間に例えると、表現力を身に付けることに似ている
また、LLMの学習方法は大きく3種類あります。こちらも、人間が学習する方法に例えてみました。
・自己教師ありの事前学習
人間に例えると、教科書や講義で学ぶことに近い
・教師あり学習によるファインチューニング
人間に例えると、テストを受けて結果を振り返ることに近い
・強化学習によるファインチューニング
人間に例えると、自分の考えを表明して賛同や批判を受けることに近い
さて、このようにLLMの中身に目を向けて考えると、どのパラメータのために学習データの質を管理するのか、リスクへ対応するためにどの学習方法でLLMを改善するのかといった視点が得られるのではないでしょうか。